
Abstract
The development and application of models, which take the evolution of network dynamics into account, are receiving increasing attention. We contribute to this field and focus on a profile likelihood approach to model time-stamped event data for a large-scale dynamic network. We investigate the collaboration of inventors using EU patent data. As event we consider the submission of a joint patent and we explore the driving forces for collaboration between inventors. We propose a flexible semiparametric model, which includes external and internal covariates, where the latter are built from the network history.
Similar content being viewed by others

1 Introduction
The analysis of network data has seen increasing interest in the recent years. Many network data thereby contain a dynamic structure, be it the development of network ties over time or observations of the network at different time points. Such data structures have led to numerous extensions of classical network models. A first paper in this direction is Robins and Pattison (2001) who propose temporal dependence in an exponential random graph model (ERGM). The idea was generalized in Hanneke et al. (2010) towards temporal exponential random graph models (tERGM). The principle idea behind the models is to include the network history as covariates in the model. This in turn forms a Markov chain of networks. The model class has been extended and generalized in various ways. Leifeld et al. (2018) focus on the implementation and added bootstrap methods for evaluating uncertainty. Krivitsky and Handcock (2014) decomposed the network dynamics into the formation of new edges and the dissolution of existing edges leading to the separable temporal Exponential Random Graph Model (stERGM).
A different strand of dynamic network models arises if time is considered as continuous. Holland and Leinhardt (1977) develop a dynamic model for social networks based on a time-continuous Markov process. Snijders (2005) and Snijders et al. (2010) extend this towards so-called stochastic actor-oriented models. The latter model is based on the assumption that the evolution of the network occurs as the consequence of small changes induced by the actors. It is further assumed that the observed network is derived from a Markov process evolving in continuous time, though the network is observed only at discrete time points. Greenan (2015) combines the approach with hazard function estimation and Cox regression models for duration time models (Cox 1972). A closely related model has been proposed by Butts (2008) for time-stamped relational data, defined as relational event model (REM), which has been used in multiple applications, see, for example, Vu et al. (2015, 2017). We also refer to Stadtfeld and Block (2017) for extensions of this model class. For time-stamped relational data, estimation can be carried out using a partial likelihood approach. Perry and Wolfe (2013) estimate a Cox multiplicative intensity model for a directed e-mail network. Vu et al. (2011) propose a continuous-time regression model for time-stamped network data. Estimation routines use an efficient partial likelihood approach focusing on large networks. This is also pursued in this paper. Instead of partial likelihood approaches, one can also make use of complete likelihood estimation, see, for example, Stadtfeld and Geyer-Schulz (2011) or Butts and Marcum (2017). A general discussion and comparison of different approaches in dynamic network modelling are found, e.g. Block et al. (2018) or Fritz et al. (2020). Our approach is in line with the Relational Event Models, but we extend the model class by including nonlinear time dynamics. In this paper, we propose a profile likelihood approach for modelling time-stamped event data for large-scale network data. The data describe the collaboration of inventors based on joint patents. The successful submission of a new patent is thereby considered as the relational event, and the number of joint patents of two inventors provides network-based count data.
In the cited papers above, all covariate effects are included linearly in the model. We propose a semiparametric approach for modelling the covariates in a more flexible way. We follow the idea of penalized spline smoothing as proposed in Ruppert et al. (2003) (see also Eilers and Marx 1996; Ruppert et al. 2009). The basic idea is to replace linear functions by spline-based functions and to achieve smoothness, penalized spline smoothing can be considered as the state-of-the-art smoothing technique. We refer to Wood (2017) for a general discussion in the framework of (generalized) regression models.
The paper is organized as follows. In Sect. 2, we introduce the patent data with some basic ideas and descriptive statistics. In Sect. 3, we give an introduction to the notation and motivate the construction of the covariates from the network history. We take a closer look on inference and derive how the model can be fitted based on a profile likelihood approach. This is extended to penalized spline smoothing. We give a brief outlook on computational issues, before we apply the proposed model in Sect. 4 to the example data. Finally, we summarize the most important issues.
2 Patent data
We will first introduce the patent data in detail before describing the model in the next section. We consider all patent applications submitted to the European Patent Office (EPO) and the German Patent and Trademark Office (Deutsches Patent- und Markenamt, DPMA), which listed at least one inventor with an address on German territory between 2000 and 2013. While this provides a comprehensive database of all inventions filed in patent applications by German inventors, we will exemplify the subsequent analysis at two selected industrial areas, namely “IT-methods” as well as “food chemistry”. Both areas have numerous patents so that data are sufficiently informative. Regarding the quality of the data, we need to emphasize that it is in principle possible that some inventors may have submitted applications directly to patent offices of other countries so that these are not in our database. In practice, however, such cases are extremely rare, since the invention would not enjoy patent protection in the inventors home country. The data were extracted from the PATSTAT database of the European Patent Office (version October 2018). For each patent, we have information about the submission day (= time stamp) and for the majority of submission the inventors geographic coordinates of their registered home address at the time of submission is also given in the data. Apparently, the registered address might not be the work address, but still we consider it as allocation proxy which will be included as covariate subsequently. To do so we assume that the inventor location stays the same until new information due to new patent submissions is given.
The data structure is apparently of bipartite type, with inventors being connected through patents. In the subsequent analysis, we focus on the relational aspect of the data by defining a relational event if two or more inventors submit a joint patent. This implies that single inventor submissions do not count as relational event while multi-inventor patent submissions lead to multiple relational events, all at the same time-point when submitting the patent. To make this point more clear, note that a patent with just two inventors corresponds to a single relational event (= one joint patent), while for instance a patent with three inventors leads to three pairwise relational ties (= three inventor pairs with a joint patent). The effect that multiple inventor patents will lead to multiple relational ties will be taken into account by an increased intensity for ties. Overall we take the inventors’ point of view and consider all bilateral joint patents as events. We also excluded four patents which had more than 20 inventors. These patents are unusual and may count as outliers. By excluding them, we guarantee that our results are not overly influenced by a few patents with a large number of inventors, but instead, describe and model the overall pattern in the data.
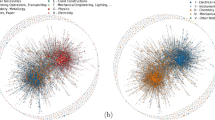
We focus on two technological areas—IT-methods (classification number 107) and food chemistry (classification number 118)—with different numbers of inventors, patents and therefore network densities. Table 1 summarizes the selected inventor networks, and Fig. 1 visualizes the network, separated for different time intervals. Compared to food chemistry, the IT-methods technological area has a higher number of inventors, but a lower number of joint patents and single owner-ship patents. The number of patents per inventor is slightly higher for food chemistry, while the number of inventors per patent is about the same in the two fields.

Visualization of two time periods of the inventor network for IT-methods (107) and food chemistry (118). Vertex size represents nodal degree. Colouring is transparent to better examine the clusters. The layout uses maximal connected components and applies the layout separately
As time stamp we choose the earliest filing date, which is aggregated on a monthly basis. To adjust for incomplete data, we select only patents from the full years 2000 till the end of 2013, resulting in 168 months. We are interested in inventors that jointly apply for patents. Therefore, we only include inventors with at least one joint patent. Note that there are of course single ownership patents in the data sets if the inventor also has joint patents.
Noticeable is that the number of observed inventor pairs applying for a patent is quite small compared to the possible number of pairs \((N(N-1)/2)\). In other words the networks exhibit a low density, which is not uncommon in large networks. We aim to restrict the analysis to active inventors. To do so, we divide the data into four periods, each of three years length. We will analyse each time interval separately and include as inventors only those who are active within the considered period. We visualize our approach in Fig. 2. We include only active inventors in the option set. An active inventor is thereby defined as a person with at least one patent within the observed time period of three years (e.g. inventor 4 or 7 in Fig. 2), or at least one patent within and one beyond the time period (e.g. inventor 6 or 8 in Fig. 2), or at least one patent before and one after the time period (e.g. inventor 5 in Fig. 2). The first two years of data from 2000 to the end of 2001 are used as “burn-in” period. We also point out, that the covariates are based on a five years retrospective interval, meaning that the inventors’ history beyond the five years is ignored in the calculation of the covariates. The selection of covariates used in our analysis is postponed to Sect. 4.1.

Definition of active inventors. The time period from 2000 till the end of 2013 is divided in four periods (2002–2004, 2005–2007, 2008–2010 and 2011–2013) of three years each. The data are aggregated on a monthly grid. The years 2000 and 2001 are used as a burn-in time
3 Poisson process network model for count data
3.1 Model description
We motivate the model by directly referring to our data example. Let \(Z_r\) be a patent indexed with a running number \(r = 1, \ldots ,R\). Each patent from one of the two considered technological areas can be defined through the following attributes:
-
\(t_r\) = time point at which patent r was successfully submitted
-
\(I_r\) = index list of inventors on patent r
-
\(z_r\) = additional covariates like geocoordinates of registered addresses of all inventors
For a set of actors (inventors) \(A = \{1, \ldots ,N\}\), we define with \({\varvec{Y}}(t) \in {\mathbb {R}}^{N \times N}\) the matrix valued Poisson process counting the number of (joint) patents. To be specific, let
for \(i,j = 1, \ldots , N\), where \(Y_{ii}(t)\) defines the number of patents of inventor i including single ownership patents. For each of the considered time intervals, we set \(t=0\) to mark the beginning of the three years period. For the network history, we go back two years, that is we look at the process for \(t \in [ -2, 3 ]\) measured in years, while the model is fitted to data for \(t \in [0 , 3]\). We define with \(Y_{ij,d} = Y_{ij} (t_{(d)})\) the evolving process, where \(0\le t_{(1)}, t_{(2)}, \ldots , t_{(m)} \le 3 \text{ years }\) is the discretized version of time at which patents have been submitted. We model the intensity of the above process as
where \(\lambda _0(t)\) is the baseline intensity and \(x_{ij}(t)\) is the covariate process, which will be defined in the following section. We assume for simplicity that both the baseline hazard and the covariate process are piecewise constant between the observed time points, that is
To write down the likelihood, we need to define two index sets. First, the events are defined through the index set \(C_d\) which is the set of all index pairs (inventor pairs) which are contributors on a joint patent at time point \(t_{(d)}\). Formally, we define this as
Secondly, we need to define the set of all inventors who are in principle able to work together. In our application, this restriction occurs from being in the same technological area and being an active inventor in the same time interval as defined above, see Fig. 2. We call this set option set and denote it as \(O_d\). These definitions lead to the log-likelihood function
Maximizing the above likelihood with respect to \(\lambda _1, \ldots , \lambda _m\) yields
and inserting this in (2) provides the profile log-likelihood
omitting all constant terms. Looking at (3), we want to point out that the baseline intensity takes into account that patents with multiple inventors lead to multiple relational events. As discussed above, a joint patent with two inventors gives one relational event, while a joint patent with three inventors already gives 3 relational events. Apparently, this is mirrored in the size \(|C_d|\), meaning that the numerator in the baseline estimate in (3) adjusts for the multiplicity of relational events resulting from patents with more than two collaborating inventors.
In principle and based on the Poisson process, we observe at each time point a single patent submission only, possibly with multiple authors. In our data, however, the time points are discretized so that at each discrete valued time point \(t_{(d)}\) we may observe more than just one submitted patent. Technically this is not a problem and does not require modifications, since in the case of multiple patent submissions the definition of the index set \(C_d\) remains unchanged, but the index pairs in \(C_d\) now refer to more than one patent submission. Again, the baseline estimate (3) is increased, this time due to multiple patents submitted at the same (discrete) timepoint.
The above profile likelihood can also be motivated through a partial likelihood approach, as shown subsequently. Let \({\varvec{Y}}_d = (Y_{ij,d})\) be the process network matrix. We now assume that the probability for a single change \(Y_{ij, d} = y_{ij, d-1} +1\) is proportional to
where \(1_{ij}\) refers to an increment of 1 in entry \(Y_{ij,d}\) and \(x_{ij, d}\) is a vector of covariates calculated from the previous process matrix \({\varvec{Y}}_{d-1}\). If \(|C_d| = 1\), i.e. only a single patent with just two inventors was submitted by inventors i and j at time point \(t_{(d)}\), we obtain
If \(|C_d| > 1\) we approximate (5) with
Taking the logarithm, we end up with the profile log likelihood given in (4). We can now easily derive the log-likelihood from Eq. (4) and obtain the score function
Defining
allows to write the second-order derivative
In the survival model context, formula (6) is also known as Breslow approximation (see Breslow 1974).
3.2 Semiparametric estimation
We now extend the model towards penalized smoothing techniques to obtain more flexibility. We therefore replace the linear predictor \(\eta _{ij,d} = x_{ij,d} \beta\) in (4) through the additive nonparametric setting
Here, \(m_{(q)}(\cdot )\) are smooth but otherwise unspecified functions. To achieve identifiability of the model, we postulate \(m_{(q)}(0) = 0\) for \(q>0\), which needs to be taken into account in the estimation. To estimate the unknown functions, we employ B-splines and replace \(m_{(q)}\) by
where \(B_{(q),k}\) is a K-dimensional B-spline basis spanning the observed range of covariate \(x_{(q)}\). (see de Boor 1978; Wood 2017).
For simplicity of notation, we now replace the index pair (i, j) by a single index l running from 1 to \(n = \frac{N \cdot (N-1)}{2}\). Consequently, we can rewrite
which in matrix form leads to
where \(B_{(q),d}\) is the B-spline basis for the q-th covariate built from rows \(B_{(q)}(x_{(q),l,d})\) for \(l = 1, \ldots , n\). Setting \(\varvec{B}_d = (B_{(1),d}, B_{(2),d}, \ldots )\) and \(\varvec{u}^T = (u^T_{(1)}, u^T_{(2)}, \ldots )\) provides the final notation.
With this notation, we can reformulate the profile likelihood in (4) as:
where \(\mathbb {1}_{C_d}\) is a vector defined as
\(\mathbb {1}_{[n \times 1 ]}\) is a vector of ones of length n.
Following Eilers and Marx (1996), we use high-dimensional bases but regularize the estimation by introducing a roughness penalty (see also Ruppert et al. 2003, 2009). This leads to the penalized smooth log-likelihood
where \(\varvec{K}(\varvec{\lambda })\) is a second-order penalty matrix. The smoothing parameter vector \(\varvec{\lambda }\) penalizes large differences in adjacent basis coefficients and can be estimated from the data. Details are provided in the Appendix B.
3.3 Computational issues
In principle, computation is straightforward, because we can derive the corresponding likelihood function and its derivatives. One should bear in mind, though, we have a huge option set of pairs of inventors for each time point. A data set with N inventors results in \(N(N-1)/2\) times T time points and therefore in about 18 million data points for, for example, \(N = 1000\) inventors and \(T=36\) months. This implies that estimation is numerically demanding, though feasible. In fact, on standard machine, the data example discussed in the next section took about 250 s to fit a linear model and about 14500 s \(\approx\) 4 h) for the semiparametric approach.
For estimating the parameters, we need to maximize the penalized smooth log-likelihood (8) with its likelihood component defined in (4). To do so, we can make use of the flexible toolbox available in the package mgcv (see Wood 2011, for further information) in the software R (R Core Team 2017). This becomes possible by considering the data and the likelihood as “survival” data and applying proportional hazard models combined with a penalized Cox Model, which in turn results through a Poisson likelihood (see Whitehead 1980). Estimation can therefore be carried out with standard routines after applying some data reorganization (see Tutz et al. 2016). At each event time \(t_{(d)}\), an artificial response variable \(y_{ij,d}\) for every inventor pair from the option set is included with \(y_{ij,d}=1\) if a patent was submitted at time \(t_{(d)}\) or \(y_{ij,d} = 0\) if not.
4 Data analysis
4.1 Covariates
We apply the proposed model to analyse the patent data described in Sect. 2. To do so, we first discuss the covariate vector \(x_{ij,d}\), which is built from the network history itself as well as additional covariates. We define network specific covariates as endogenous, while the additional covariates are exogenous.
We start with network related covariates, which are described below and visualized in Fig. 3. Simple descriptive analyses are listed in Table 2. First, we take the total number of patents of inventor i and j at time point \(t_{(d-1)}.\) That is
We refer to this quantity as “patents_ij”. Moreover, the number of previous “joint_patents” of inventor i and j is included as covariate, which is calculated through
Furthermore, a so-called 2-star statistic (“2-star”) is included, which expresses the number of inventors that hold a joint patent with inventor i or j. This is obtained through
A common choice in network analysis is also “triangle” statistics. This counts the number of inventors that jointly hold a patent with i and j:
Note that the number of patents (\(x_{(1)}\)) as well as the number of joint patent holders (\(x_{(2)}\)) expresses the centrality of the inventors with respect to number of patents and number of collaborative patents, respectively. A summary of the distribution of the network-related covariates is given in Table 2. We emphasize that covariates \(x_{(1)}\) and \(x_{(2)}\) are correlated by construction, which also applies to \(x_{(3)}\) and \(x_{(4)}\). This should be taken into account when interpreting their effects.

Visualization of covariates from network history of a toy network graph: number of patents of inventor i and j with \(x_{(1),ij,d} = 6 + 8\) (black edges), including self-loops (single ownership patents) and multiple patents (first panel). Number of joint patents of inventor i and j with \(x_{(2),ij,d} = 2\) (black edges), counting the number of edges of i and j (second panel). Number of inventors that hold a joint patent with inventor i or j with \(x_{(3),ij,d} = 3 + 5\) (black nodes in third panel). Number of inventors that jointly hold a patent with i and j with \(x_{(4),ij,d} = 2\) (black nodes), counting k twice because of a multi-patent (fourth panel)
As exogenous covariates we include the inventor-pair-specific distance in kilometres, that is
where \(s_{i,d}\) are the geocoordinates of the address of inventor i and \(s_{j,d}\) accordingly and \(|| \cdot ||\) denotes the Euclidean distance. We assume that the inventors do not move until new location information on the basis of submitting a new patent becomes available. To avoid leverage effects, we truncate distances over 1000 kilometres to 1000 kilometres.
4.2 Results
We start with a slightly simpler model than proposed and replace the smooth functions by simple linear functions. This easily allows to compare the effects for the two technology areas for the different time periods. All models include the above mentioned structural covariates “patents_ij”, “joint_patent”, “2-star”, and “triangle”, and the exogenous covariate “distance [100 km]”. Figure 4 compares the estimates for the four considered time periods. The different technology areas show more or less the same behaviour. The biggest difference can be seen for the variable joint_patent. The more joint patents two inventors have, the more likely they collaborate in the future. The estimates for 2-star and triangle are quite small. The distance in 100 kilometres has a negative effect on the patents meaning that inventors with regional proximity are collaborating more likely.

Estimates for different covariates, technological areas and time periods. For each of the four areas and four covariates, we have four estimates for the time periods with the corresponding errorbars (standard error \(\times\) 2)
Next we explore the linearity and extend the model using smooth effects. If linearity holds, this will be visible in the semiparametric fit, where the fitted smooth function gets a linear line, or, accordingly, if the confidence bands do not include a linear shape. We therefore fit the same model but now using the semiparametric estimation with splines as proposed. In Fig. 5 we show exemplary for the second time period the fit of the model for the two technological areas. Estimates for the remaining time intervals can be found in the Appendix. From Fig. 5 we see that some functional shapes of the curves shown are more or less linear. This demonstrates that the linear model from above seems suitable for this effect. Some other effects uncover a nonlinear shape, which is what we emphasize and interpret now. The sum of patents of inventor i and j has a negative effect, which is clearly nonlinear. In fact, we can see some saturation, meaning that for IT (left panel) the negative effect gets stronger until about 3 patents and then stays stable. In contrast, the number of joint patents has a positive and strong effect, which in fact is clearly linearly. This means that if the inventors have already submitted several own patents (with other inventors or even single inventor patents), their affinity of being involved in new patents decreases nonlinearly. On the other hand, if the inventor pair has already joint patents in the past, they are more likely to work together in future. The effect of joint patents is linear for the IT industry, while for food and chemistry (right panel) there is a nonlinear effect. Note that the linear effect, as shown in Fig. 4, primarily expresses the slope of the functional effect for small number of joint patents, but the linear effect is not able to express the effect for larger number of joint patents.

Estimated smooth effects for IT-methods (left panels) and food chemistry (right panels) area and second time period
The effect of the structural statistics like the number of inventors that hold a joint patent with inventor i or j (2 star), respectively, does not show a significant tendency. The effect of the number of inventors that jointly hold a patent with i and j(triangle) has a small positive bounded influence, even though not that strong than the number of joint patents. Again, we see nonlinearity, in particular for triangle). Moreover, the geographical distance of two inventors plays an important rule. There is a larger positive effect for small distances, which decreases nonlinearly with increasing distance. For distances larger than 250 kilometres, the effect is almost zero or negative. This means that if there is a certain distance between the inventors, it does not matter how many kilometres exactly. All in all, Fig. 5 uncovers nonlinear effects, so that the semiparametric approach appears to be justified.

Estimated smooth effects for “joint_patent” of food chemistry (118) area and different time periods
Figure 6 visualizes the positive effects of “joint_patent” for the four time periods exemplary for the food chemistry area. Each time period lasts 36 months. The tendency of the effects is about the same for all periods; there is a steep increase at the beginning, which then becomes bounded. In period three and four, the effect decreases and increases, respectively, at the end of the observation period. This should not be interpreted too strictly as the frequency of more than 10 joint patents is quite low. We can see similar behaviours for the other areas (see Appendix).
Finally, we compare the linear and the semiparametric model by looking at the AIC value (Wager et al. 2007). The results are given in Table 3, where the minimum AIC value for each model comparison is set to zero. We see that for each time interval and for both industries, the semiparametric model is preferred. This indicates the necessity to include nonlinear components in the model.
5 Conclusion
In this paper we propose a flexible approach to model large-scale dynamic network data with structural and exogenous covariates. Our approach is based on a profile likelihood method exploiting well-established estimation routines. We apply this idea to a large data set of patents submitted jointly by inventors from Germany between 2000 and 2013. We show advantages of including covariates in a semiparametric and therefore flexible way. The results show the driving forces in collaboration of inventors and demonstrate their behaviour over time. The models can be fitted with standard software employing the link to the Cox model and therefore invite to be used in other data constellations as well.
References
Block, P., Koskinen, J., Hollway, J., Steglich, C., Stadtfeld, C.: Change we can believe in: comparing longitudinal network models on consistency, interpretability and predictive power. Soc. Netw. 52, 180–191 (2018)
Breslow, N.: Covariance analysis of censored survival data. Biometrics 30(1), 89–99 (1974)
Butts, C.T.: A relational event framework for social action. Sociol. Methodol. 38(1), 155–200 (2008)
Butts, C.T., Marcum, C.S.: A relational event approach to modeling behavioral dynamics. In: Group Processes, vol. 59–92. Springer, Cham (2017)
Cox, D.R.: Regression Models and Life-Tables. J. R. Stat. Soc. Ser. B (Methodological) 34(2), 187–220 (1972)
de Boor, C.: A Practical Guide to Splines, vol. 27. Springer, New York (1978)
Eilers, P.H., Marx, B.D.: Flexible Smoothing with B-splines and Penalties. Stat. Sci. 11(2), 89–102 (1996)
Fritz, C., Kauermann, G., Lebacher, M.: Tempus volat, hora fugit—a survey of tie-oriented dynamic network models in discrete and continuous time. Stat. Neerlandica 74, 275 (2020)
Greenan, C.C.: Diffusion of innovations in dynamic networks. J. R. Stat. Soc. Ser. A (Statistics in Society) 178(1), 147–166 (2015)
Hanneke, S., Fu, W., Xing, E.P., et al.: Discrete temporal models of social networks. Electron. J. Stat. 4, 585–605 (2010)
Holland, P.W., Leinhardt, S.: A dynamic model for social networks. J. Math. Sociol. 5(1), 5–20 (1977)
Krivitsky, P.N., Handcock, M.S.: A separable model for dynamic networks. J. R. Stat. Soc. Ser. B (Statistical Methodology) 76(1), 29–46 (2014)
Leifeld, P., Cranmer, S.J., Desmarais, B.A.: Temporal exponential random graph models with btergm: estimation and bootstrap confidence intervals. J. Stat. Softw. 83(1), 1–36 (2018)
Perry, P.O., Wolfe, P.J.: Point process modelling for directed interaction networks. J. R. Stat. Soc. Ser. B (Statistical Methodology) 75(5), 821–849 (2013)
R Core Team: R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria (2017)
Robins, G., Pattison, P.: Random graph models for temporal processes in social networks. J. Math. Sociol. 25(1), 5–41 (2001)
Ruppert, D., Wand, M.P., Carroll, R.J.: Semiparametric Regression. Cambridge University Press, Cambridge (2003)
Ruppert, D., Wand, M.P., Carroll, R.J.: Semiparametric regression during 2003–2007. Electron. J. Stat. 3, 1193–1256 (2009)
Snijders, T.A.: Models for longitudinal network data. Models Methods Soc. Netw. Anal. 1, 215–247 (2005)
Snijders, T.A., Van de Bunt, G.G., Steglich, C.E.: Introduction to stochastic actor-based models for network dynamics. Soc. Netw. 32(1), 44–60 (2010)
Stadtfeld, C., Block, P.: Interactions, actors, and time: dynamic network actor models for relational events. Sociol. Sci. 4, 318–352 (2017)
Stadtfeld, C., Geyer-Schulz, A.: Analyzing event stream dynamics in two-mode networks: an exploratory analysis of private communication in a question and answer community. Soc. Netw. 33(4), 258–272 (2011)
Tutz, G., Schmid, M., et al.: Modeling Discrete Time-to-Event Data. Springer, New York (2016)
Vu, D., Lomi, A., Mascia, D., Pallotti, F.: Relational event models for longitudinal network data with an application to interhospital patient transfers. Stat. Med. 36(14), 2265–2287 (2017)
Vu, D., Pattison, P., Robins, G.: Relational event models for social learning in MOOCs. Soc. Netw. 43, 121–135 (2015)
Vu, D. Q., Hunter, D., Smyth, P., Asuncion, A. U.: Continuous-Time Regression Models for Longitudinal Networks. In Advances in Neural Information Processing Systems, pp. 2492–2500 (2011)
Wager, C., Vaida, F., Kauermann, G.: Model selection for penalized spline smoothing using akaike information criteria. Aust. N. Z. J. Stat. 49(2), 173–190 (2007)
Whitehead, J.: Fitting Cox’s regression model to survival data using GLIM. J. R. Stat. Soc. Ser. C (Applied Statistics) 29(3), 268–275 (1980)
Wood, S.N.: Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J. R. Stat. Soc. B 73(1), 3–36 (2011)
Wood, S.N.: Generalized Additive Models: An Introduction with R, 2 Rev Chapman & Hall/Crc Texts in Statistical Science, Boca Raton (2017)
Acknowledgements
The project was partially supported by the European Cooperation in Science and Technology [COST Action CA15109 (COSTNET)].
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Further results

Estimated smooth effects for IT-methods (left panels) and food chemistry (right panels) area and first time period

Estimated smooth effects for IT-methods (left panels) and food chemistry (right panels) area and third time period

Estimated smooth effects for IT-methods (left panels) and food chemistry (right panels) area and fourth time period
Appendix B: Technical details
The second-order difference penalty matrix can be defined as
with dimension \([P\cdot K \times P\cdot K ]\) and \([K \times K ]\), respectively. P is the number of covariates. The second-order penalty matrix \(\varvec{K}\) can be derived from \(\varvec{K}_{(p)} = \varvec{D}^T_2 \varvec{D}_2\) where \(\varvec{D}_2 = \varvec{D}_1 \varvec{D}_{2-1}\) is a recursively obtained difference matrix with
with dimension \([(K-1) \times K ]\). The corresponding derivatives to apply the Newton–Raphson algorithm are straightforward:
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bauer, V., Harhoff, D. & Kauermann, G. A smooth dynamic network model for patent collaboration data. AStA Adv Stat Anal 106, 97–116 (2022). https://doi.org/10.1007/s10182-021-00393-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10182-021-00393-w